
MS Windows
Journaux liées à cette note :
Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Ajout de packages dans des distributions atomiques".
Chrome OS et Android implémentent la stratégie de double partition A/B (seamless) system updates.
Cette technologie offre des mises à jour complètement transparentes en arrière-plan et un redémarrage immédiat.
En revanche, contrairement à la solution CoreOS (méthode détaillée dans cette note), cette méthode a pour inconvénient de consommer deux fois plus d'espace de stockage.
MacOS s'appuie sur les snapshots de son filesystem APFS (fonctionnalité qu'offre aussi btrfs). Cela garantit un retour en arrière rapide vers la version antérieure si des problèmes surviennent.
En revanche, l'upgrade se termine durant le reboot, pouvant prendre de 2 à 5 minutes, alors que le redémarrage reste instantané avec Chrome OS, Android, CoreOS ou Fedora Silverblue.
Comme d'habitude, je n'arrive pas à trouver des informations précises sur le fonctionnement interne de MS Windows 😔. D'après Claude Sonnet 4, le système de mise à jour de Windows 10 et Windows 11, baptisé Unified Update Platform (UUP), semble plutôt daté : pas d'A/B (seamless) system updates, absence d'atomicité, installation longue lors du reboot (10 à 30 minutes), possibilité d'échec en cours de processus, rollback complexe, aucun système de snapshot comparable à MacOS. J'ai du mal à croire ce bilan tellement catastrophique, ce qui m'amène à questionner sur l'exactitude des informations rapportées par Claude Sonnet 4.
D'après cette documentation particulièrement riche et mes recherches complémentaires, je pense que la stack libostree + composefs (avec zstd:chunked ) tel qu'implémenté dans Fedora CoreOS est probablement la technologie de mise à jour la plus avancée actuellement disponible.
Avant de présenter le fonctionnement du système de mise à jour de Fedora CoreOS en 2025, je vais retracer l'évolution technique de cette solution.
Note suivante : "CoreOS de 2013 à 2018".
Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora
J'envisage de proposer à ma mère et à ma compagne de se prêter à une expérimentation : une transition en douceur vers des portables sous GNU/Linux, avec mon assistance complète durant tout le processus.
Leur situation actuelle :
- Pour ma compagne : d'un Macbook Air 13" 3ième génération, modèle de 2015, acheté en 2018 à moins de 1000 €, qui tourne bien entendu sous MacOS. Usage principal : navigation web.
- Pour ma maman : un laptop de plus de 10 ans sous MS Windows. Usage principal : Microsoft Word, Microsoft Excel, impression, navigation web.
Choix de la distribution Linux : une Fedora version n-1 (voir la note 2024-01-29 pour plus d'informations sur ce choix).
Plus précisément, j'envisage d'utiliser l'édition Fedora Silverblue, une variante immutable (ou « atomic ») de Fedora Workstation qui propose l'environnement de bureau GNOME.
Je souhaite configurer et rendre très facilement accessibles les applications Signal et RustDesk :
- Signal pour facilement échanger avec moi en cas de difficulté ;
- RustDesk pour me permettre de prendre directement le contrôle du desktop à distance, pour les aider.
Pour ma maman, je souhaite lui faire tester Libre Office. Pour éviter de la perturber avec les formats de fichier, je souhaite configurer Libre Office pour qu'il enregistre par défaut au format de Microsoft Word et Microsoft Excel.
Je souhaite installer quelques extensions GNOME pour que l'environnement Linux ressemble au maximum à MS Windows, par exemple :
Je souhaite leur proposer un laptop qui répond aux caractéristiques suivantes :
- si possible à moins de 1000 € ;
- entre 14 et 15 pouces, avec une résolution verticale de 1200 pixels minimum ;
- 16Go de RAM ;
- un trackpad et un châssis avec un maximum de qualité ;
- idéalement convertible en 2 en 1 ou 3 en 1 ;
- silencieux ;
- support GNU/Linux parfait ;
Pour le moment, j'ai identifié les modèles suivants :
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
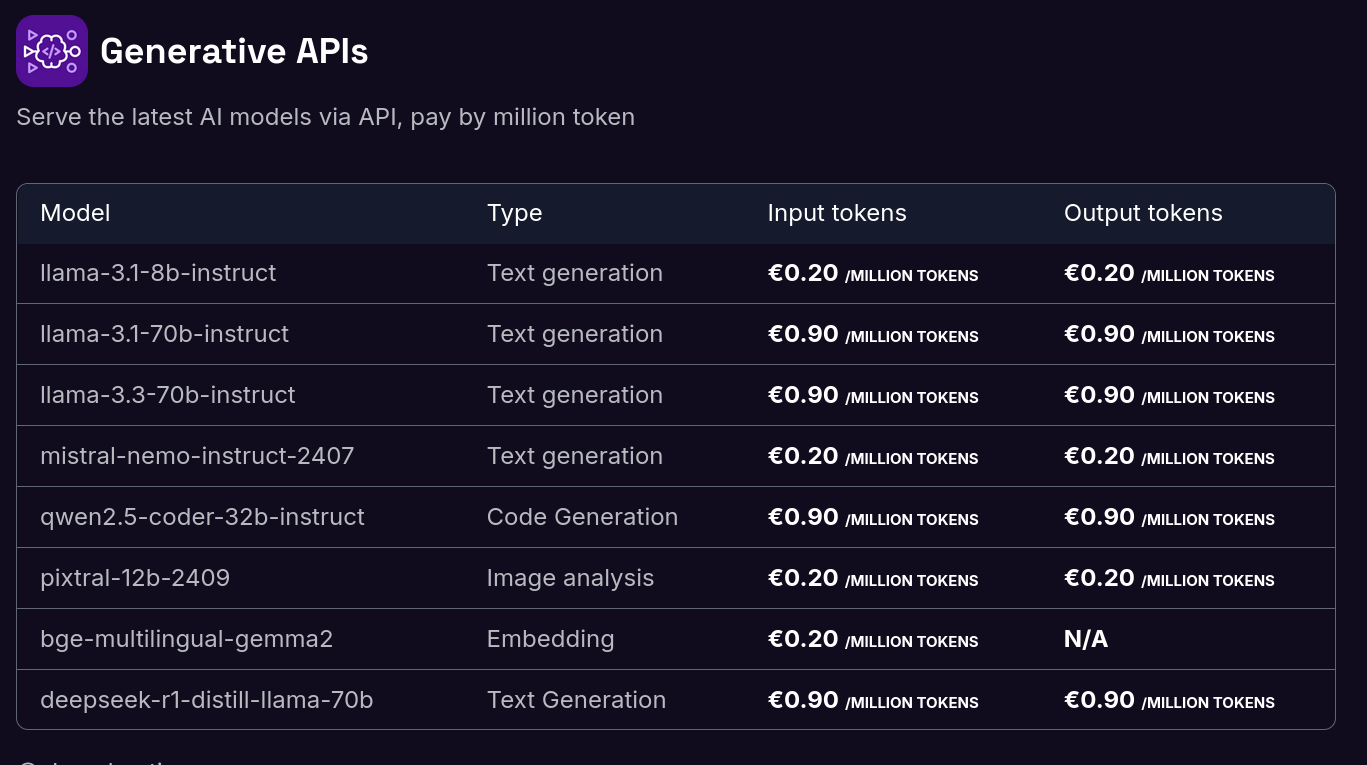
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
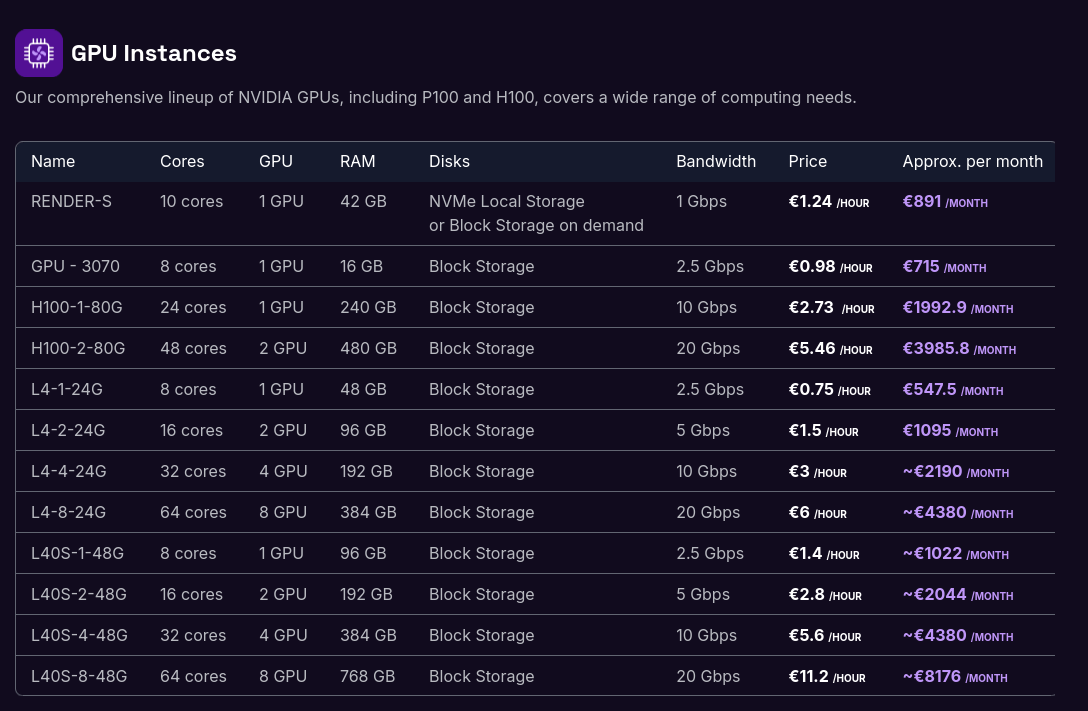
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Merci à Alexandre 🤗 qui a pris le temps de tester l'installation sous WSL2 du playground que j'ai présenté dans "Playground qui présente comment je setup un projet Python Flask en 2025".
Le playground : https://github.com/stephane-klein/mise-python-flask-playground
Après quelques petites corrections https://github.com/stephane-klein/mise-python-flask-playground/commits/main/ Alexandre a réussi avec succès à installer et lancer tous les services sous Windows 11 avec WSL2.
C'est une très bonne nouvelle 🙂.
Cela ajoute une « corde à mon arc ». Jusqu'à présent, je précisais bien que mes development kit n'étaient pas compatible MS Windows. Je le mentionnais même dans mes annonces d'embauche, pour ne pas surprendre les candidats.
Maintenant, mes environnements de développement sont compatibles Linux, MacOS, et Linux 🙂.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du mardi 04 février 2025 à 16:46
Je souhaite créer un playground d'un development kit pour Python + PostgreSQL (via Docker) + Flask + Flask-Migrate, basé sur Mise.
J'ai la contrainte suivante : le development kit doit fonctionner sous MS Windows !
Je me dis que c'est une bonne occasion pour moi de tester Windows Subsystem for Linux 🙂.
Problème : je ne possède pas d'instance MS Windows.
#JaiDécouvert que depuis 2015, Microsoft met à disposition des ISOs officiels de MS Windows :
- ISO pour Windows 10 : https://www.microsoft.com/fr-fr/software-download/windows10ISO
- ISO pour Windows 11 : https://www.microsoft.com/fr-fr/software-download/windows11
- Virtual machine MS Windows pour VirtualBox et d'autres : https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/
J'ai testé dans ce playground le lancement d'une Virtual machine MS Windows avec Vagrant : https://github.com/stephane-klein/vagrant-windows-playground.
Cela a bien fonctionné 🙂.
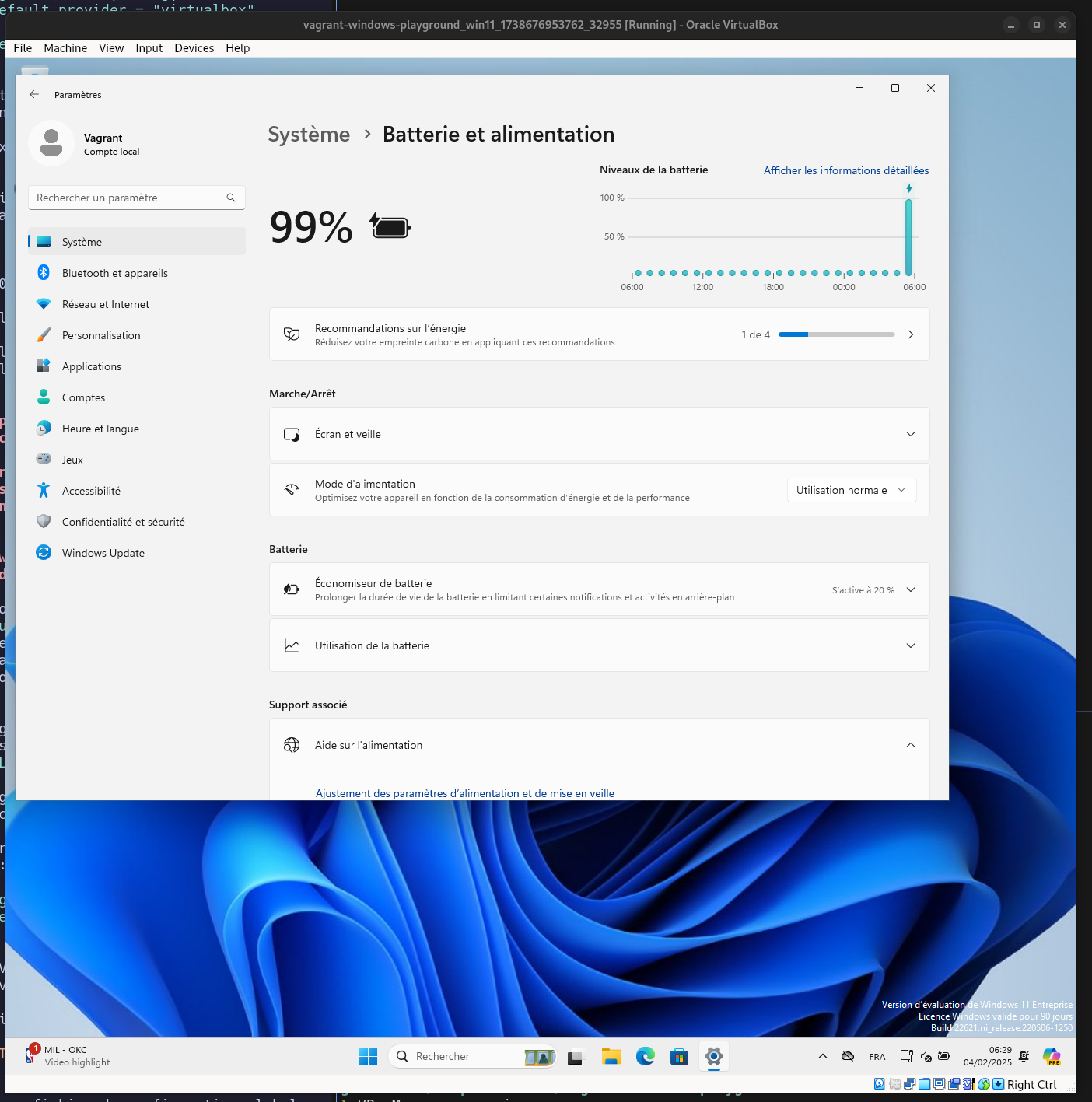
J'ai aussi découvert le repository windows-vagrant qui semble permettre de construire différents types d'images MS Windows avec Packer. Je n'ai pas essayé d'en construire une.
Journal du lundi 09 septembre 2024 à 21:33
#JaiLu Windows NT vs. Unix: A design comparison (from).
Je ne connais rien au kernel MS Windows, j'ai trouvé cela intéressant.
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
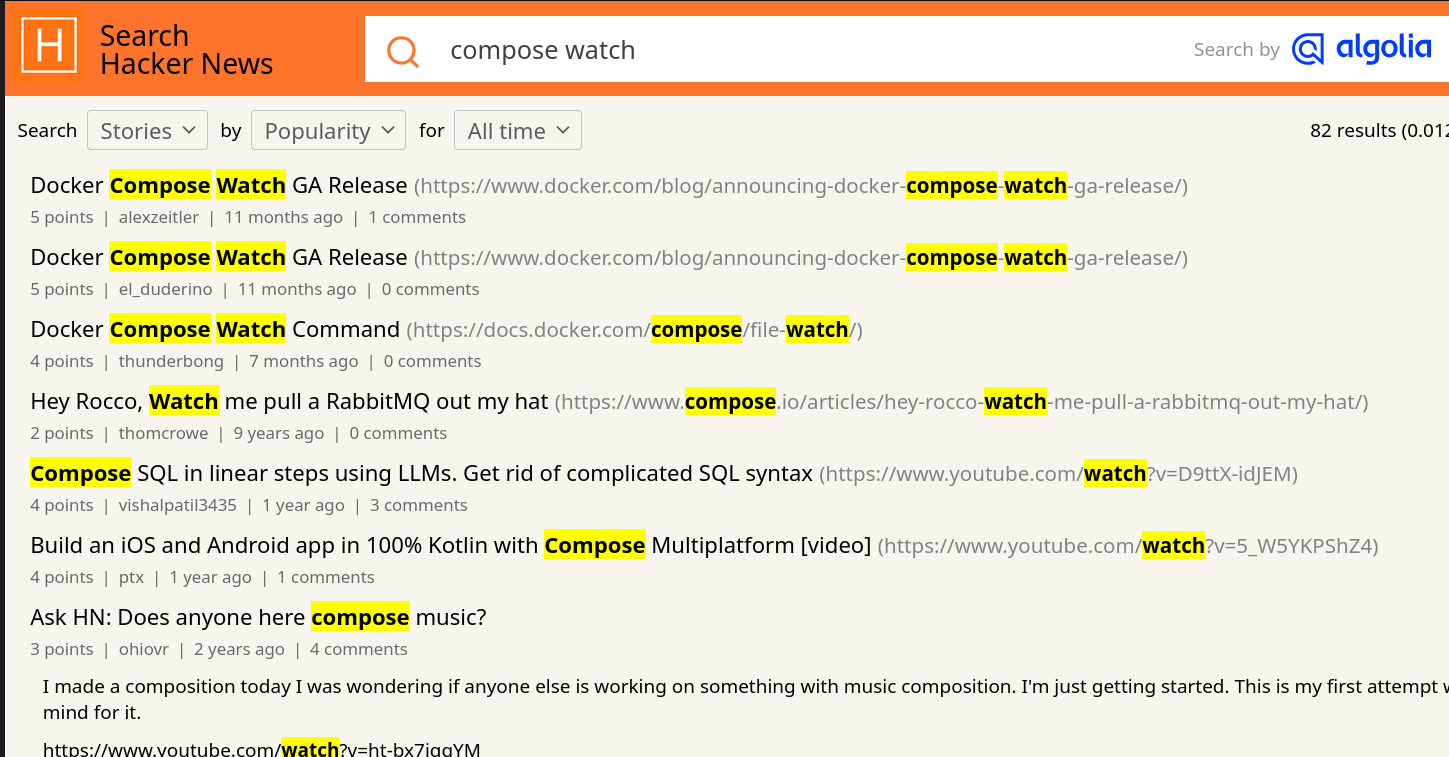
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.